ZFS in details
ZFS is a combined file system and logical volume manager designed by Sun Microsystems. The features of ZFS include protection against data corruption, support for high storage capacities, integration of the concepts of filesystem and volume management, snapshots and copy-on-write clones, continuous integrity checking and automatic repair, RAID-Z and native NFSv4 ACLs.
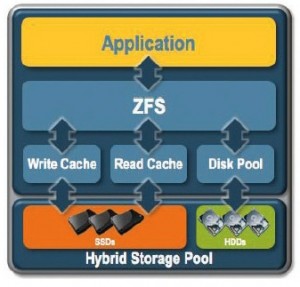 What is ZFS?
What is ZFS?
- ZFS stands for “Zetabyte File System” and is a powerful storage system that combines a volume manager and a file system.
- ZFS is transactional, Copy-on-Write and always consistent. When new data need to be written, ZFS will use new blocks instead of overwriting the previous ones, so that the old version still remains available. Furthermore, ZFS works in a transactional way, similar to the databases. If you benchmark ZFS, all operations will be stored in a transaction group (TXG) and the queries will be executed in burst every 30 seconds.
- ZFS is 128 bits, rising its capacity to 256 quadrillion zettabytes (ZB), where a zettabyte is 270 bytes.
- ZFS uses checksums to verify data integrity
- ZFS loves RAM and SSDs, and knows how to use them. ZFS use RAM as smart cache (ARC: Adaptive Replacement Cache) and stores up to 4 cache lists: MRU (Most Recently Used), MFU (Most Frequently Used) and 2 others.
The RAM is also used as a prefetch space and “Vdev Read-Ahead”, ZFS stores in RAM the data that you have the most chance to ask, so that the transfer can be as fast as possible.
ZFS is base don 2 commands: zpool for creating pools and zfs for creating datasets
Creating a pool
A pool is created with the command:
zpool create pool_name disk1 disk2 disk3 zpool status
The first command creates the pool, while the second one shows its status and mounting point. A df -h will show you the free space available, which corresponds to the sum of the disks capacity (striping).
The storage space is available and can be used directly but then you would miss the datasets functionalities.
Creating a dataset
A dataset is a wrapper in which properties can be configured. The datasets list can be shown using zfs list. Their creation is also very simple:
zfs create pool_name/dataset_name
This will create the dataset and mount it automatically under the ZFS root, here pool_name (do not confuse with the OS root).
The zpools and their vdevs
A pool is created from one or more “vdevs” (Virtual Devices), which combine one or more devices. Those vdevs can be of type:
- disk: a real disk drive. To show the disk drives connected to your BSD system, you can do a:
camcontrol devlist diskinfo -v /dev/ada0
- file: a file (/vdevs/vdisk001), easy to use for testing but not recommended for production. Those files have to be at least 128MB pre-allocated with the following command under BSD:
dd if=/dev/zero of=vdisk001 bs=1024k count=128
- mirror: one or more disks in mirror (RAID1)
- raidz1/2: three or more disks in RAID5/6. The raidz2 is in fact a raidz1 with a double parity check
- spare: a spare disk
- log (aka ZIL SLOG): a device dedicated for logging (usually an SSD)
- cache (aka L2ARC): a device dedicated to read-cache (usually an SSD)
Those vdevs can be combined together to create hybrids pools, for example:
zpool create (-f) mypool mirror disk1 disk2 mirror disk3 disk4
creates a RAID1+0 made from 2 vdevs (2 mirrors). The -f is necessary to create a pool that has the same name as a previously deleted one.
zpool create mypool raidz disk1 disk2 disk3 log ssd1 cache ssd2 spare disk4 disk5
creates an hybrid pool made from 4 vdevs
Scrubs
A scrub will verify the whole data contained in the pool, check their consistency and repair errors if any.
The zpool scrub command should be run frequently with a cron. Once a week outside work hours should be sufficient.
Portability
The pools can be imported and exported. During the reboot, the ZFS configuration is exported during the shutdown and then imported at startup. In a similar way, disks can be moved to another machine, a simple zpool import will allow to bring back the ZFS pool thanks to the configuration data stored in the header of the disks.
Maintenance
A defect disk can easily be replace by a spare one with the command:
zpool replace old_dev new_dev
The devices can be put to “offline” (to work on it without ZFS taking care of what happens) or “online” with the commands:
zpool online vdev1 zpool offline vdev1
The rebuild of a vdev is called a “resilver”.
The commands zpool attach and zpool detach allow to add or remove devices from a redundant vdev (mirror).
Increasing the size of a pool
A pool can extended with the command
zpool add pool_name vdev
It’s not possible for the moment to lower the size of a pool (shrink).
Properties
The properties can be displayed using:
zpool get all pool_name
and modified with
zpool set autoreplace=on dataset_name
Amongst the properties of a pool, the most important ones are failmode, autoreplace and listsnapshots.
The failmode describes how ZFS will react if anything goes wrong: WAIT for the problem to solve, CONTINUE even if there is a problem, PANIC to stop the system.
Listsnapshots allows to show or hide the snapshots when a zfs list is issued (hidden by default).
Autoreplace allows to automatically replace a defect drives by a spare one.
History
zpool history dataset_name
will show all the commands that have been run on the specified dataset.
Sizing
ZFS reserves 1/64th of the pool capacity to save data used for the Copy-on-Write.
The datasets
The datasets are control points, they can be nested and inherits the properties from their parent (called “stub” if they are just containers, like the “home” folder). To create a dataset, use:
zfs create mypool/dataset
The ZVols
The ZVols are datasets representing a volume instead of a file system. This volume can be partitionned, formatted in ext3/ext4 or other, and can be created in “thin provisioning” (sparse). ZVols are used with iSCSI to provide LUNs.
Properties
The properties can be displayed with:
zfs get all pool/dataset
and modified with
zfs set key=value pool/dataset
- Disk space used vs Disk space referenced:
The used disk space represents the space used by the data, while the referenced disk space includes also the space used by the snapshots. - Quota vs Reservation
The quota will set a limit, while the reservation will pre-allocate space. As an example, you will prefer to use a quota for simple users and a reservation for VIPs. - Record size
ZFS uses dynamic block sizing, but the maximum size is specified by the record size. This property should not be modified, unless you are doing some fine-tuning for databases (if it’s the case, you will prefer a record size of 8k). - Mount point
Defines the mount point - Share NFS
Exports the dataset to make it a NFS - Checksum
It’s not recommended to disable the checksum because it provides a data integrity mechanism while its impact on the overall performances is very low. - Compression
Allows to compress data - atime
Keeps a trace of the files access time, which is of no use. You can disable it with:zfs set atime=off pool_name
- copies
Set the number of copies to create during data-writing. This is only useful when you have a pool of one disk and you want to have many copies of your data in case an area of the disk gets corrupted. - sharesmb
Allows to share the dataset through Samba (CIFS) - ref_quota and ref_reservation
Same as for the quotas and reservations but this time with the reserved space
The snapshots
A snapshot is an instant image of the current state of the data. A restore can be done file by file or with the whole dataset. A snapshot is identified by the symbol @. Due to the Copy-On-Write functionality, the snapshots are not taking any additional space. To take a snapshot, you can use:
zfs snapshot pool/dataset@snapshot_name
If the snapdir property is set to “visible” (instead of “hidden”), you will see a directory called .zfs that contains all the snapshots directories. Thos directories can be browsed like any file system (in read-only) to recover data.
Rollback
The rollback function allows to restore a snapshot and cannot be undone. the more recent snapshots are then lost.
Clones
The clone function creates a dataset (read-write) from a snapshot. This clone acts exactly like a normal dataset, except that it’s not taking any space. This is useful to test an environment with older data without any impact for the actual data.
A clone can be promoted to break dependency with the previous dataset and have its own.
The clones can be replicated, by streaming them to a pipe:
zfs send pool/dataset@snap1 | ssh root@remote_machine zfs recv pool/dataset_backup
Here we sent the snapshot through ssh on another machine, but we could have aswell sent it to an encrypted file.
Shares
ZFS allows to easily share datasets via NFS, CIFS and iSCSI by setting the corresponding property to “on”.
Monitoring I/O
2 ways to measure input/output:
- on the Virtual File System (VFS) level with fsstat (most important)
- on the physical disk level with iostat
Conclusion
The ZFS system is very simple and it’s not its only strength. The mechanisms hidden behind are the product of an efficient reflexion that has led this project to a strong solution. This will for sure modify in a good way the habits of the system and storage admins.
Trackback from your site.